zhangdd谈ceph(一)初识ceph
最近在研究ceph分布式存储,刚开始接触时感觉很混乱,无从下手的感觉。于是根据以往经验,先网上看各种资料,一个字 感觉乱,各种配置 各种环境 各种bug 各种坑,没办法了 买书从头开始,开始买了ceph中国社区的《ceph分布式存储实战》,如果你是新手刚接触的话,不要迟疑买了吧。然后通读了一遍,感觉稍微有了点头绪,于是按照套路,本地装虚拟机,经典三节点先上测试环境跑一遍看看,心里有点底,最后都捋顺了,基本的配置也有点明白了,做规划,生产环境与测试环境不同,需要考虑各种因素,只有全方位考虑好了,才能开始正式部署。
在此把从开始接触到完成配置的过程记录一下,也希望能帮到一些同样有需要的同学。
今天第一篇,ceph历史此处不在多说,大家只需清楚ceph的最大特点:充分发挥存储本身的计算能力和去除所有的中心点。
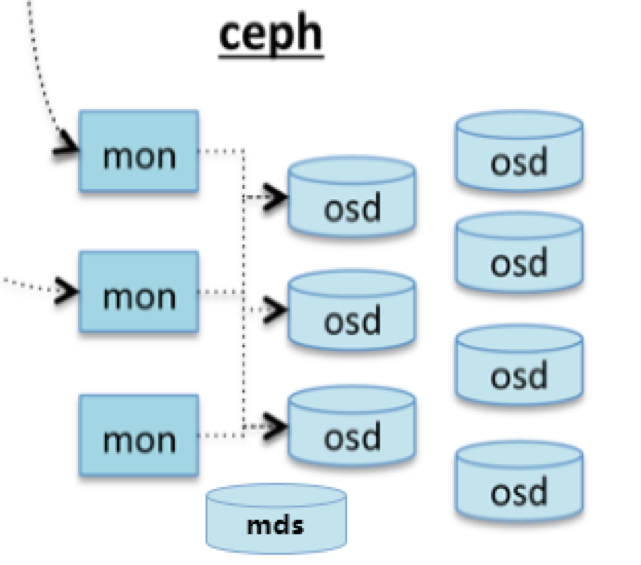
基础的ceph包含monitor、 osd,如果你需要用到cephfs还需要一个mds
本文后续的配置不管虚拟机还是正式环境 都会使用centos7.4 环境,请使用Ubuntu的同学绕路,谢谢。
一、概述
Ceph是一个分布式存储系统,诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目。随着云计算的发展,ceph乘上了OpenStack的春风,进而成为了开源社区受关注较高的项目之一。
Ceph有以下优势:
- CRUSH算法
Crush算法是ceph的两大创新之一,简单来说,ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。Crush算法有相当强大的扩展性,理论上支持数千个存储节点。
- 高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域,支持数据强一致性; ceph可以忍受多种故障场景并自动尝试并行修复。
- 高扩展性
Ceph不同于swift,客户端所有的读写操作都要经过代理节点。一旦集群并发量增大时,代理节点很容易成为单点瓶颈。Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长。
- 特性丰富
Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。在国内一些公司的云环境中,通常会采用ceph作为openstack的唯一后端存储来提升数据转发效率。
二、CEPH的基本结构
Ceph的基本组成结构如下图:
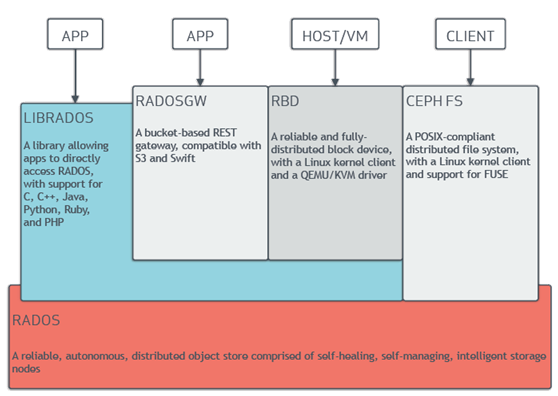
Ceph的底层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
CEPHFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所以无需调用用户空间的librados库。它通过内核中的net模块来与Rados进行交互。